Sequence context-specific profiles for homology searching
10-Mar-2009
PNAS, 2009, 106 no.10, 3770-5 published on 10.03.2009
PNAS, online article
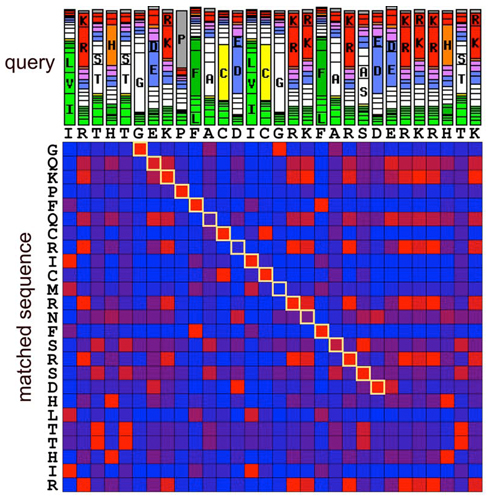
Sequence alignment and database searching are essential tools in biology because a protein’s function can often be inferred from homologous proteins. Standard sequence comparison methods use substitution matrices to find the alignment with the best sum of similarity scores between aligned residues. These similarity scores do not take the local sequence context into account. Here, we present an approach that derives context-specific amino acid similarities from short windows centered on each query sequence residue. Our results demonstrate that the sequence context contains much more information about the expected mutations than just the residue itself. By employing our context-specific similarities (CS-BLAST) in combination with NCBI BLAST, we increase the sensitivity more than 2-fold on a difficult benchmark set, without loss of speed. Alignment quality is likewise improved significantly. Furthermore, we demonstrate considerable improvements when applying this paradigm to sequence profiles: Two iterations of CSI-BLAST, our context-specific version of PSI-BLAST, are more sensitive than 5 iterations of PSI-BLAST. The paradigm for biological sequence comparison presented here is very general. It can replace substitution matrices in sequence- and profile-based alignment and search methods for both protein and nucleotide sequences.