
moCluster: Identifying Joint Patterns Across Multiple Omics Data Sets
14-Dec-2015
J. Proteome Res., 15 (3), pp 755–765, DOI: 10.1021/acs.jproteome.5b00824
J. Proteome Res., online article
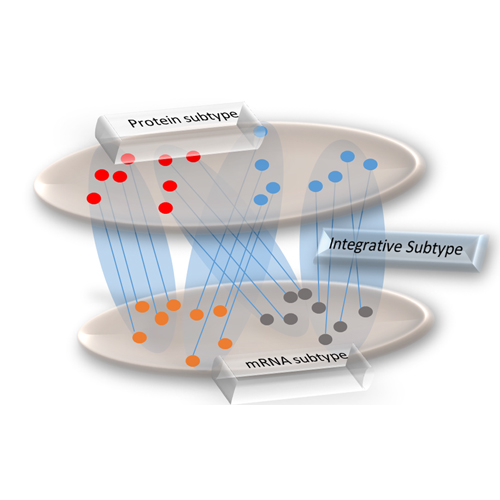
Increasingly, multiple omics approaches are being applied to understand the complexity of biological systems. Yet, computational approaches that enable the efficient integration of such data are not well developed. Here, we describe a novel algorithm, termed moCluster, which discovers joint patterns among multiple omics data. The method first employs a multiblock multivariate analysis to define a set of latent variables representing joint patterns across input data sets, which is further passed to an ordinary clustering algorithm in order to discover joint clusters. Using simulated data, we show that moCluster’s performance is not compromised by issues present in iCluster/iCluster+ (notably, the nondeterministic solution) and that it operates 100× to 1000× faster than iCluster/iCluster+. We used moCluster to cluster proteomic and transcriptomic data from the NCI-60 cell line panel. The resulting cluster model revealed different phenotypes across cellular subtypes, such as doubling time and drug response. Applying moCluster to methylation, mRNA, and protein data from a large study on colorectal cancer patients identified four molecular subtypes, including one characterized by microsatellite instability and high expression of genes/proteins involved in immunity, such as PDL1, a target of multiple drugs currently in development. The other three subtypes have not been discovered before using single data sets, which clearly illustrates the molecular complexity of oncogenesis and the need for holistic, multidata analysis strategies.